格灵深瞳视觉基础模型Glint
近日,格灵格灵深瞳灵感实验室和华为伦敦研究所发布最新版视觉基础模型——Glint-MVT v1.5(RICE)。深瞳视觉
格灵深瞳此前有6篇论文亮相国际顶级学术舞台ICCV 2025,基础涵盖视觉基座模型、模型人脸3D重建等领域,格灵其中最新版MVT的深瞳视觉相关论文不仅入选,还被接收为Highlight论文。基础
先看升级后的模型核心要点:
1技术创新性方面:新版MVT提出了一种区域局部感知增强的视觉特征学习方法。
2下游任务表现方面:在OCR和分割等任务上效果优于v1.1版和AIMv2、格灵SigLIP2。深瞳视觉
3此外,基础团队还构建了共4亿图像、模型20亿局部区域、格灵4亿文字区域的深瞳视觉预训练数据集。
概括来说,基础MVT v1.5的最大升级在于:强化了模型对图像细节和文字特征的捕捉和表达能力,在精细任务上表现更优。
以往的视觉-文本对比学习模型,如OpenAI的CLIP模型和谷歌的改进版SigLIP模型等,更侧重全局图像特征(对图像内容的概括性描述),核心的训练逻辑是 “全局对齐”,让模型理解图像的整体语义,并和文本的整体语义相对应。
但这类模型对图像局部区域的细节信息表达较少,难以满足需要精细处理图像的任务,例如OCR和图像分割等。
针对这一问题,新版MVT提出一种区域局部感知增强的视觉特征学习方法。
在技术方案上,格灵深瞳团队利用专家分割模型和OCR模型,对无标注数据进行处理,产生十亿级局部区域,并通过聚类产生伪标签。也就是说,通过分割-OCR-聚类的技术流程,团队将无标注数据转化为带伪标签的大规模训练集,节约了标注成本,提升了自主学习能力。
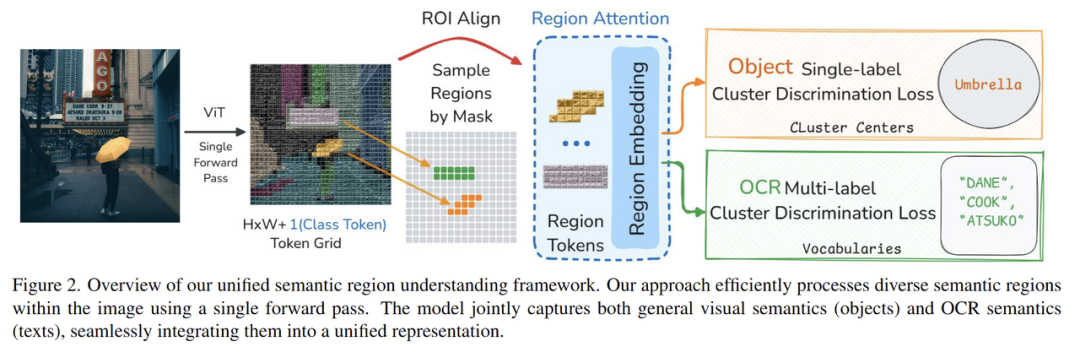
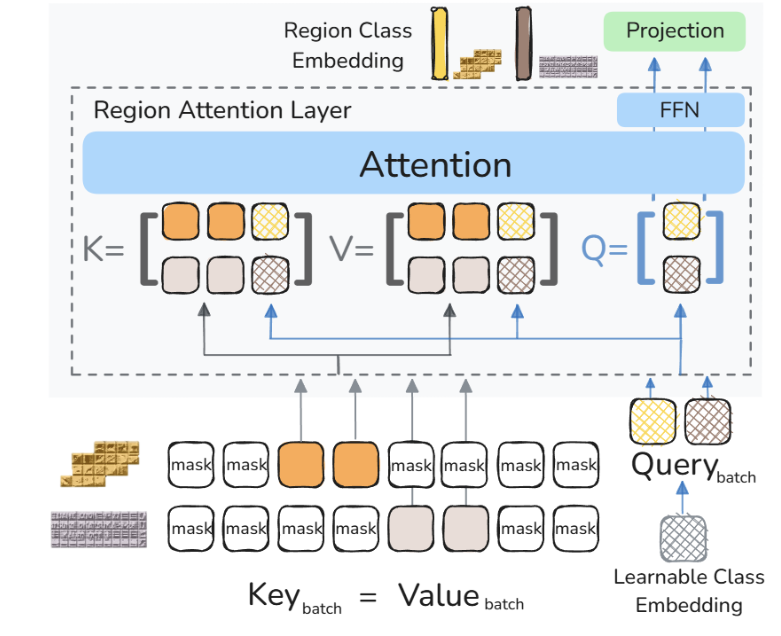
同时,团队设计了区域Transformer层,用来提取局部区域特征和支持数据扩展的区域鉴别损失,使得团队能在亿级数据上进行预训练,突破了在大规模样本上进行高效训练的技术挑战。
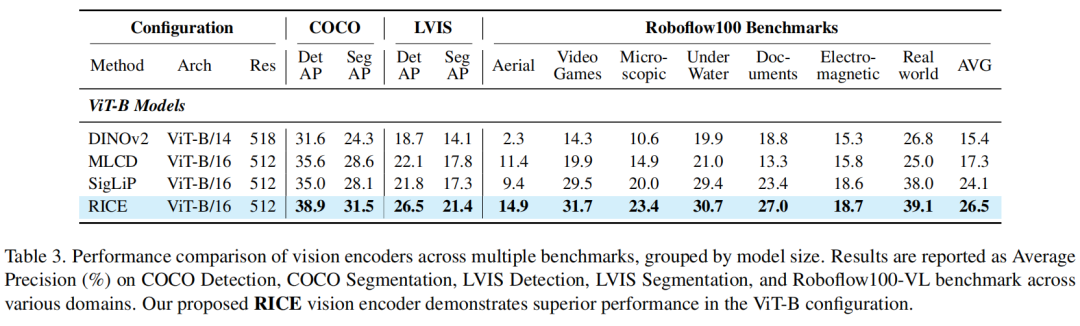
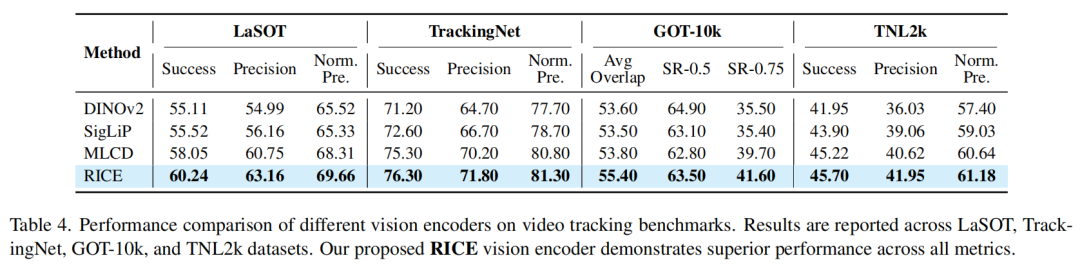
基于以上技术攻关,MVT v1.5增强了局部特征和文字特征。相较于传统的全局图像特征模型,新版MVT在检测分割、OCR等对应的下游任务表现上得到提升,有效性得到验证。
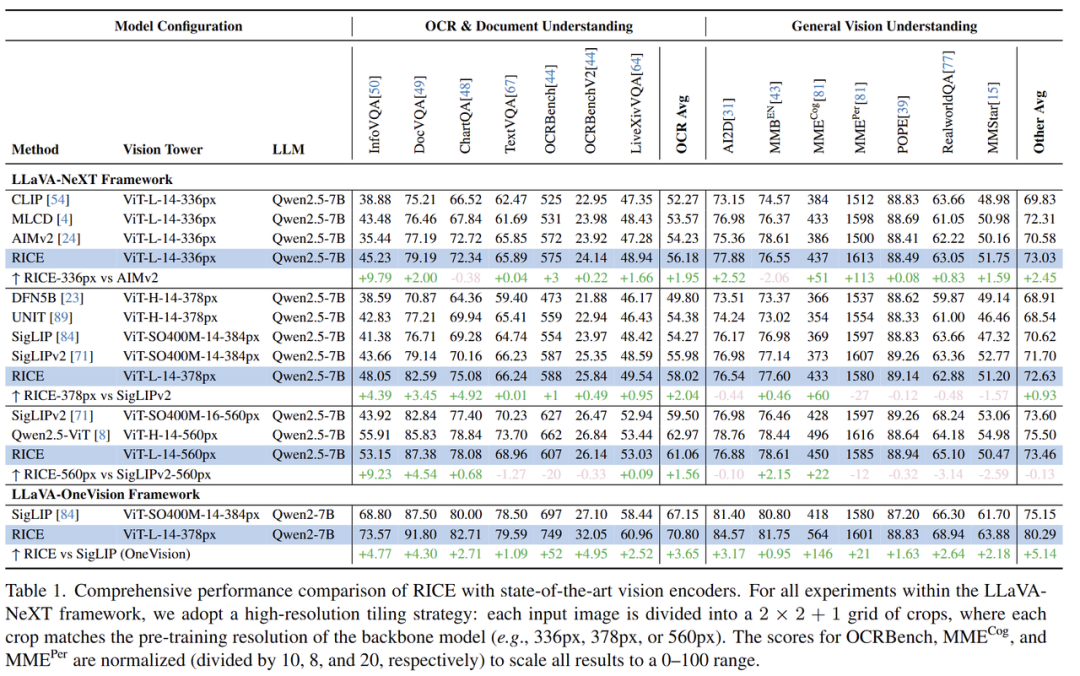
以文字OCR任务为例,从下图可以看出,MVT v1.5(RICE)的多项分数高于CLIP和SigLIP等模型。
文字OCR任务和全局理解任务:
引用分割:
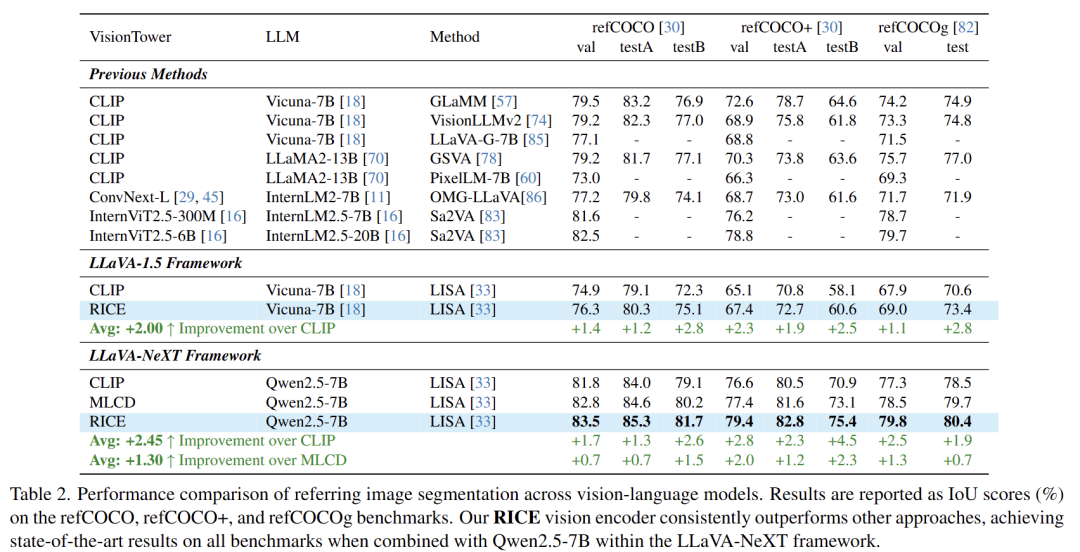
检测分割任务:
单目标跟踪任务:
从技术创新到下游任务,格灵深瞳并非单纯追求学术表现,而是注重技术成果转化应用,通过提升任务表现推动AI在多元场景中真正落地。
MVT v1.5背后的技术团队——格灵深瞳灵感实验室,是国内计算机视觉领域的深耕者。灵感实验室聚焦于视觉及相关模态特征表达与应用,主要研究方向包括:视觉基础大模型、多模态大模型、图文多模态表征、大规模分布式训练等。下一步,团队将锚定视频理解领域,发布最新模型成果。
相关文章
 全力以赴,不负韶华!不忘初心,砥砺前行!——大业美家集团总裁王云先生9月18日上午,华东理工大学党委书记、党委副书记、党办主任及对外联络处等校领导,以及原核工业部企业管理局领导等华东理工大学在京部分校2025-08-27
全力以赴,不负韶华!不忘初心,砥砺前行!——大业美家集团总裁王云先生9月18日上午,华东理工大学党委书记、党委副书记、党办主任及对外联络处等校领导,以及原核工业部企业管理局领导等华东理工大学在京部分校2025-08-27
污水处理一级水二级水三级水是什么意思?(二级水和一级水区别是什么)
污水处理一级水二级水三级水是什么意思?二级水和一级水区别是什么) 标签: 添加时间:2022-11-21 浏览次数:30972025-08-27 临近三月,各大展会活动纷纷进入预热阶段,汽车照明行业逐渐呈现出一番热闹景象。与此同时,不少企业试图通过借助资本力量实现企业的产能夸张。面对整体行业的扩张态势,业内提醒企业商家“急躁冒进是大2025-08-27
临近三月,各大展会活动纷纷进入预热阶段,汽车照明行业逐渐呈现出一番热闹景象。与此同时,不少企业试图通过借助资本力量实现企业的产能夸张。面对整体行业的扩张态势,业内提醒企业商家“急躁冒进是大2025-08-27
天下晨間新聞 臉書、Google為什麼說不惜退出香港?|天下雜誌
香港一項修法,是否真的會讓科技巨頭大出走?另外,油價要飆了嗎?您的閱讀篇數已達上限立刻訂閱全閱讀,即可享全站不限篇數閱讀2025-08-27 掘金2年超5千万报价韦德 名记:闪电侠会留热火发布时间:2016-10-03 10:56 来源:豫都网 我来说说 我要投稿[摘要]北京时间7月6日,根据ESPN名记马克-斯特恩透露,丹佛掘金队向全明星2025-08-27
掘金2年超5千万报价韦德 名记:闪电侠会留热火发布时间:2016-10-03 10:56 来源:豫都网 我来说说 我要投稿[摘要]北京时间7月6日,根据ESPN名记马克-斯特恩透露,丹佛掘金队向全明星2025-08-27 程力牌东风国六洒水车人人都会错过,人人都曾经错过,真正属于你的,是在这里等你的程力牌东风国六洒水车。此款车型的外形尺寸为7690X2520X3200mm),整车的总质量为16000kg),整备质量为62025-08-27
程力牌东风国六洒水车人人都会错过,人人都曾经错过,真正属于你的,是在这里等你的程力牌东风国六洒水车。此款车型的外形尺寸为7690X2520X3200mm),整车的总质量为16000kg),整备质量为62025-08-27
最新评论